Honeycomb 2 - What are all these new terms?

This is a continuation of Part 1.
If you happened to grow up in New Zealand in the 80's and 90's, as I did, or you're wondering who the chap in the image above is, you might want to look at this, just for nostalgia sake.
So, to recap, we now have data going into Honeycomb, but it's talking directly from the lambda to their api, during the call. And the data going in there is rather messy.
So, I need to do two things: break that API dependency, and understand the terms and conventions of Honeycomb.
I'm used to having metrics and logs, and not having them mix very much. Honeycomb is a bit different in that it deals with events which are then rolled up into traces. You can almost think of an event as a log line - something happened and I want to know about it - but it's also a data structure, so you can add any other context you want to it.
This "other context", unlike most systems, is encouraged to be high cardinality. Do put your userId in here. This is normally discouraged by most metrics systems, as it breaks their storage model - or you bill, badly. Sam Stokes, one of the Honeycomb engineers, talks about the how and why here.
The direct match to what I had was pretty much
- Log lines become events (spans)
- Metrics either become single events if we need a data point, or just context on the current event
- ... or they get deleted because they are no longe relevant. This happened a lot.
Remember, we are just starting this platform from nothing, so we didn't have a lot of legacy, or even tho a good idea of what the platforms failure modes look like yet.
Initially, I'd added a lot of metrics around timings - how long are certain operations taking, did we mess up a database query etc. Honeycomb, however, adds a duration_ms property to every event, so around 90% of the metrics I had created had no purpose anymore - just wrap the thing I want to time in an event, and I get a log-line-like event, with timing.

The shot above shows a few of these - a single point in time event ( gql.start ) which has various bits added like the GraphQL query, some default user ids and other bits we can pull out of the request.
The second line - appointments.query- is a database call, which was originally a metric with how long the request took. This rendered down an event, which comes with the timing, as well as having the SQL, (some) parameters, returned row count, and other useful fields added.
The POST under it is the auto-instrumentation of honeycomb - it hooks into http, https , mongodb and other libraries, so we get the URL, return code etc (we are using DataApi, so all of our database access is over HTTPS). I find this useful for some things, like calls to Stripe and Twilio, but for our database calls to AWS RDS DataApi, they are just noise. I'll take them as-is for the moment tho, and our wrapping spans (appointments.query for eg) have the other info we want, like the text of the query, parameters if appropriate, and number of rows returned.
Once I really got events sorted in my head, I found it fairly easy to move the existing code over to using them - I still have a load of logger.debug to change over, but they are rendering to events now, which is useful if a bit noisy.
It also resulted in a much better developer experience - we can see the events in the console, with the context displayed inline and in formatted JSON, rather than big blobs of unreadable and unformatted JSON. It's reduced the noise a lot.
The last thing which has been kind of tripping me up is our incorrect use of await. Node has an async subsystem, which keeps track of the stack when you use async and await, and other libraries can hook into this.
The way we were doing it (below) was fine in general - tho you lose it out of the stack trace - but the beeline also hooks into this chain and it gets very confused.
const getConversations = async () => conversations.getAll();In this case, we have an async function (getConversations) calling another async functions (conversations.getAll()) but not awaiting the result. As far as I can tell, this returns a Promise<Promise<Conversation[]>> which gets auto-unrolled to a Promise<Conversation[]>, so we don't notice. Correcting it is pretty simple:
const getConversations = async () => await conversations.getAll();It doesn't always break the honeycomb tracing, but more often than not, it does. It looks like this when it breaks:
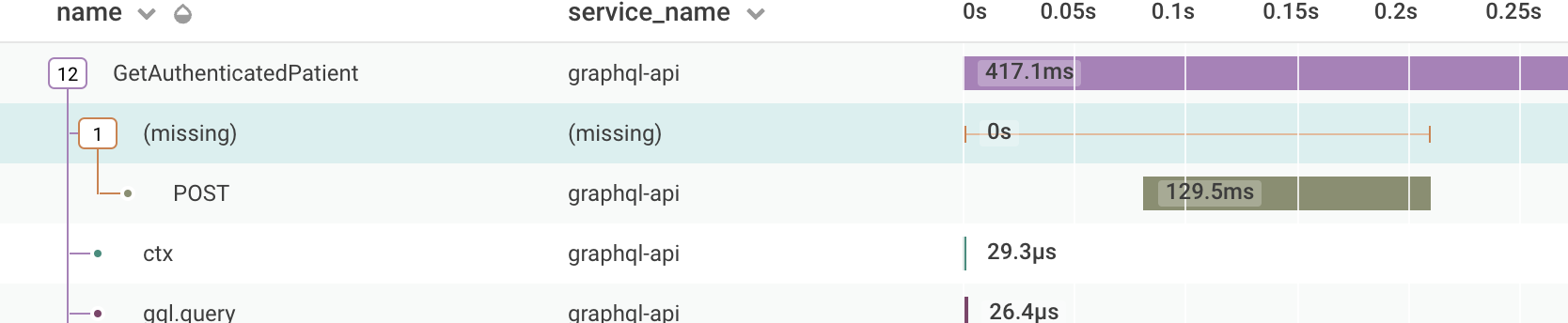
The POST (which is in getAll) has no parent span, so the visualisation has no idea where to put it. Fairly easy fix, but it took a while to work out why. ESLint provides some rules around this too - no-floating-promises should highlight those pretty quickly.